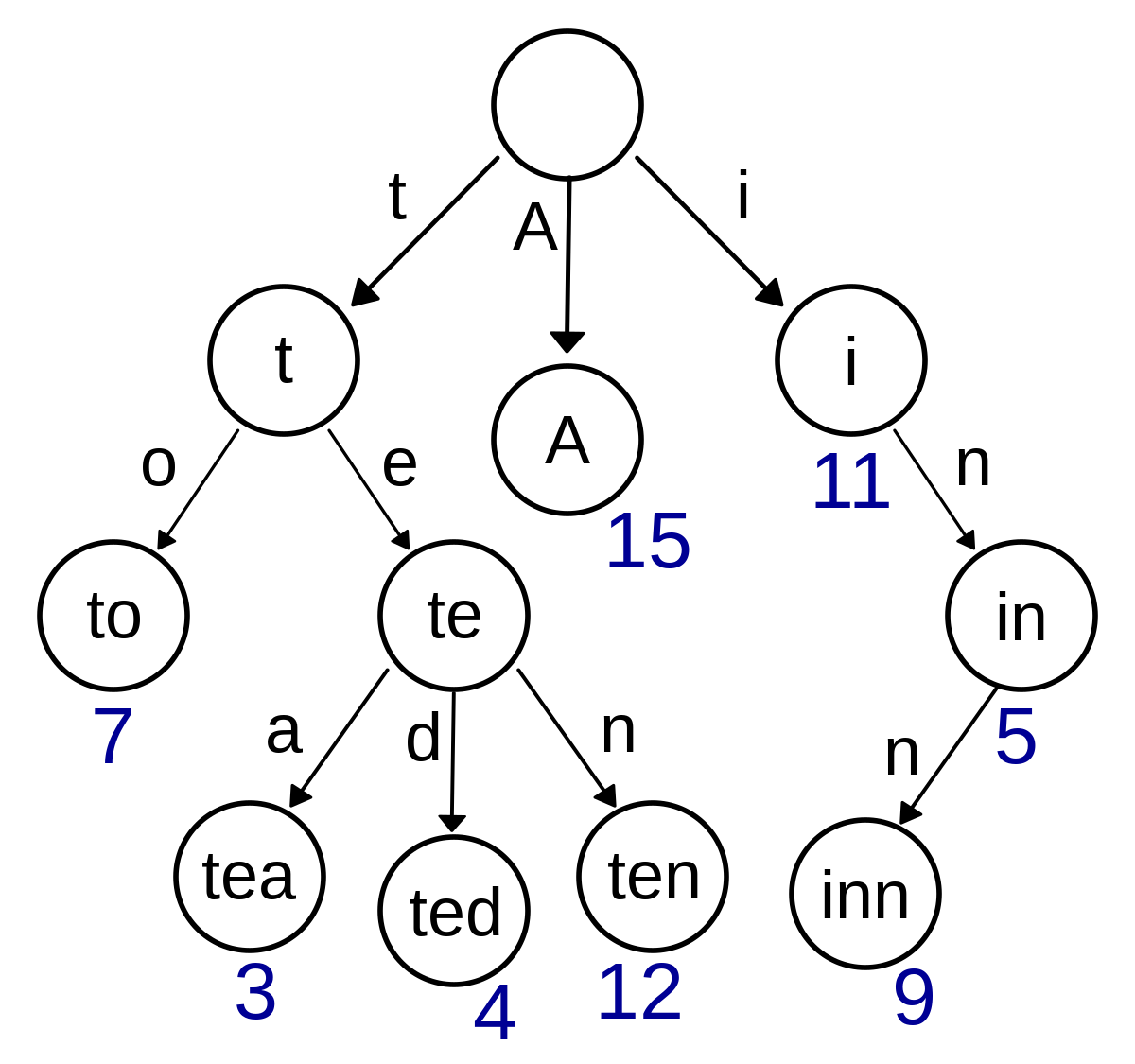
// 插入操作 voidinsert(char str[]){ int p = 0; for (int i = 0; str[i]; i ++) { int u = str[i] - 'a'; if (!son[p][u]) son[p][u] = ++ idx; p = son[p][u]; } cnt[p] ++; }
// 查询操作 intquery(char str[]){ int p = 0; for (int i = 0; str[i]; i ++) { int u = str[i] - 'a'; if (!son[p][u]) return0; p = son[p][u]; } return cnt[p]; }
constint N = 1000010; int son[N][26], cnt[N], idx;
voidinsert(string &str){ int p = 0; for (int i = 0; i < str.size(); i ++) { int &s = son[p][str[i] - 'a']; if (!s) s = ++ idx; p = s; } cnt[p] ++; }
intquery(string &str){ int res = 0, p = 0; for (int i = 0; i < str.size(); i ++) { int u = str[i] - 'a'; if (!son[p][u]) break; p = son[p][u]; res += cnt[p]; // 注意要在 son[p][u] 赋值给 p 之后统计数量,否则统计的是以前一个字符结尾的数量 } return res; }
intmain(){ int n, m; cin >> n >> m; string str; while (n --) { cin >> str; insert(str); } while (m --) { cin >> str; cout << query(str) << endl; } return0; }
classSolution { public: // 注意,面试中应以结构体形式书写 structNode { int cnt; Node *son[26]; Node() { cnt = 0; // 注意此处的 & 符号,若忽略了些符号,则初始化失败,son数组中储存的是野指针 for (Node* &s : son) s = nullptr; } } *root; string replaceWords(vector<string>& dictionary, string sentence){ root = newNode(); int n = sentence.size(); for (string word : dictionary) { insert(word); } string res = ""; int i = 0, j = 0; // 对单词进行分割 while (i < n) { while (i < n && sentence[i] != ' ') i ++; string sub = sentence.substr(j, i - j); res += query(sub); if (i < n) { i = i + 1, j = i; res += " "; } elsereturn res; } return res; }
voidinsert(string &word){ Node *p = root; for (int i = 0; i < word.size(); i ++) { int u = word[i] - 'a'; if (!p->son[u]) p->son[u] = newNode(); p = p->son[u]; } p->cnt ++; }
string query(string &word){ string res; Node *p = root; for (int i = 0; i < word.size(); i ++) { int u = word[i] - 'a'; if (!p->son[u]) return word; p = p->son[u]; if (p->cnt) return word.substr(0, i + 1); } // 若字典中的单词比句子中的单词更长(即句子中的单词是字典中单词的前缀),则直接返回句子中的单词。 return word; } };
constint M = 3100010; // 因为最多有 100000 个整数,而每个整数最多 31 位,故最多 M 节点 int son[M][2], idx;
voidinsert(int x){ int p = 0; // 一定要注意要从高位到低位进行存储和查找,否则找到的可能不是最大值 for (int i = 30; ~i; i --) { int u = x >> i & 1; if (!son[p][u]) son[p][u] = ++ idx; p = son[p][u]; } }
intcheck(int x){ int p = 0, tmp = 0; for (int i = 30; ~i; i --) { int u = x >> i & 1; if (son[p][!u]) { tmp += 1 << i; p = son[p][!u]; } else p = son[p][u]; } return tmp; }
intmain(){ int n; cin >> n; int tmp, res = 0; for (int i = 0; i < n; i ++) { cin >> tmp; insert(tmp); res = max(res, check(tmp)); } cout << res << endl; return0; }
constint N = 100010, M = 3100010; int s[N], son[M][2], idx, cnt[M];
// x:插入的元素的值 // s:若为 1 则为插入元素,若为 -1,则为删除元素 voidinsert(int x, int s){ int p = 0; for (int i = 30; i >= 0; i --) { int u = x >> i & 1; // 使用 cnt 数组存储当前节点对应的集合的元素个数,每删除一个数,对应的值减 1 if (!cnt[son[p][u]]) son[p][u] = ++ idx; p = son[p][u]; cnt[p] += s; } }
intquery(int x){ int p = 0, res = 0; for (int i = 30; i >= 0; i --) { int u = x >> i & 1; if (cnt[son[p][!u]]) p = son[p][!u], res = res * 2 + 1; else p = son[p][u], res *= 2; } return res; }
intmain(){ int n, m; cin >> n >> m; int t; for (int i = 1; i <= n; i ++) { cin >> t; s[i] = s[i - 1] ^ t; } int res = 0; insert(s[0], 1); // 注意要先把前缀和第一个元素 s[0] 插入 for (int i = 1; i <= n; i ++) { if (i - m - 1 >= 0) insert(s[i - m - 1], -1); // 超过最大数据长度 M,删除元素 res = max(res, query(s[i])); insert(s[i], 1); } cout << res << endl; return0; }